TF*IDF
With the TF*IDF formula, you can identify in which proportion certain words within a text document or website are weighted compared to all potentially possible documents. This formula uses the term frequency and can be used for OnPage optimization to increase the relevance of a website for the search engines, without the keyword density playing a role alone in this.
TF
TF is short for “Term Frequency”. It determines a term’s (a word or a combination) relative frequency within a document. The term frequency is being compared to the relative occurrence of all remaining terms of a text, document or website. The formula uses a logarithm and reads as follows:
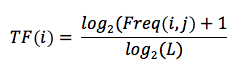
The logarithm makes sure a vast increase of the main keyword doesn’t lead to an improved value within the calculation. While the keyword density merely works out a single word’s percentage distribution compared to the total number of words in a text, the “Term Frequency” also factors in the proportion of all words used in a text.
IDF
IDF calculates the “Inverse Document Frequency” and completes the term evaluation analysis. It acts as the TF’s corrective. The Inverse Document Frequency is important in order to include the frequency of documents for a certain term into the calculation. The IDF compares the number of all known documents with the number of texts containing the term. The logarithm also “compresses” the results here.
![]()
Hence the IDF determines a text’s relevancy with regard to a certain keyword.
The multiplied formulas show a document’s relative term evaluation compared to all potentially possible documents containing the same keyword. In order to receive useful results, the formula needs to be performed for any meaningful word within a text document.
The bigger the database used for the TF*IDF calculation, the more precise the results.
Benefit for SEO
When talking of TF*IDF in terms of Search Engine Optimisation, users of common tools are aimed at creating texts as unique as possible for a website or subpage in order to rank as high as possible for certain search terms in the SERPs. For a long time, the keyword density was used primarily as benchmark for texts optimised for search engines. The TF*IDF provides a much more precise way of optimising content.
As search engines more often try to interpret the semantic relation between the terms, it can be of advantage to semantically optimise a website’s content. This is called Latent Semantic Optimization.
A TF*IDF tool can serve for the determination of keywords that should be used ideally in the website’s content. With the help of a TF*IDF tool, texts cannot only be optimised regarding a certain keyword but the tool also points out, during the creation of a text, which terms should be included in a text in order to make it as unique as possible.
Disadvantages of TF*IDF
If texts are being optimised by means of the Term Frequency analysis, the user needs to be aware of that all elements of a website that are being included into the analysis. Meaning that headlines of categories, as well as product descriptions are being considered. Especially for online shops, that only want to present a single product on a site, the TF*IDF formula will be a rather suboptimal possibility for improving content as this kind of OnPage optimisation requires a lot of text. This is due to the fact that this formula is more far-reaching and calculates the value of every term within the document.
Beyond that, the TF*IDF formula doesn’t consider that search terms can appear cumulatively, that stemming rules can apply or that texts increasingly apply synonyms.
TF*IDF is not a secret weapon for content optimization, but it provides the possibility of being able to create content as original as possible. The optimization of texts is essentially one possible aspect of an on-page optimization. Even the best text that has been created with TF*IDF won't counterbalance bad badlinks or mobile pages that are not optimized.
Further, text agencies, authors or webmasters shouldn't orientate themselves only to TF*IDF. The results of the tool are calculations based on logarithms. Other aspects such as tonality, call to action, structure or reading flow don't play a role in the weighting of terms. These aspects should however be considered when creating a text.
Background
The online marketing expert Karl Kratz played a significant role in the spreading and popularity of the TF*IDF formula in Germany. In his article from 2012, "SEO Myth Keyword Density", he made the TF*IDF formula for weighting texts known, and roused the SEO community, which has previously mostly used keyword density for the creation of texts.
With the formula TF*IDF no new rules were created for the optimization of texts; the weighting of terms, which was developed and analyzed in 1957 by the computer researcher Hand Peter Luhn from IBM within the scope of information retrieval, was simply newly discovered. Before term weighting was rediscovered for search engine optimization, it was also used in linguistics as well as computer linguistics for the evaluation of text material.