WDF
WDF (Within Document Frequency) is the weighting of a word in a document. The term comes from the information statistic which determines the frequency and weighting of words in documents and from this derives a ranking of the documents based on relevance. In conjunction with the Inverse Document Frequency, the WDF provides a formula that allows the uniqueness of a text to be determined with respect to a keyword or keyword combination.
Background
The calculation of this frequency was developed by Donna Harman in her article “Ranking Algorithms” within the volume “Information Retrieval: Data Structures & Algorithms” in 1992 to give specific expressions a weighting in a document. [1]
This researcher has been active in the field of information retrieval since the mid-1980s and has routinely taken part in conferences. The calculation of the WDF serves the preparation of datasets in information science. Frequently, WDF is mentioned together with IDF and the weighting value P, since these quantities multiplied with each other represent a weighting formula, which can determine the uniqueness of text material with respect to certain keywords. As a rule, the higher the WDF, the more often a term occurs in a document.
Libraries can use WDF to make searches through their inventory easier. Users are provided with search results that show the best possible results for a specific search term not solely based on keyword density, but context can also be taken into account.
Calculation of WDF
The formula for the Within Document Frequency - WDF is as follows:
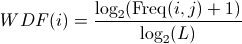
i=:word
j=:document
L=:total number of words in document j
freq (i,j)=:frequency of the word i in document j
Explanation to "+1":
if freq(i,j) = 0, then "+1" would result in the counter log showing 2(1) = 0.
Example
Suppose a document contains 12,000 words. Assumption L = 12000. The word i appears 23 times in this document, therefore freq (i,j)=23. When using these values, the following calculation results:
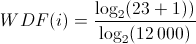
The weight value WDF(i)=0.3 (rounded) is the result. The relative frequency of the word i here is 0.001%.
WDF versus keyword density
The weighting within a document is represented by the Within Document Frequency. The value is comparable to Keyword Density which is often used in content optimization. In contrast, the WDF is calculated for meaningful words and not by a simple rule of three.
Two logarithms are used to prevent the WDF value from being artificially increased by the massive addition of keywords in the text body. Basically, the calculation of the WDF can be used to determine the term or terms which best describe a text. Eric Kubitz speaks in his blog of the “DNA of the text.”
Relevance to SEO
The groundbreaking article by Karl Kratz “SEO-Myths Keyword Density” from 2010 gave a boost and a new purpose to information retrieval methods developed in the 1990s and earlier. For example, (WDF*IDF)] has turned upside down previous content optimization based on keyword density and today is practically the standard for the search engine optimized web contents.
References
- ↑ W.B. Frakes, R. Baeza-Yates (Hgg): Information Retrieval: Data Structures & Algorithms. Prentice Hall 1992, S. 363-392