Inverse Document Frequency
Inverse Document Frequency (IDF) in information science and statistics, is a method of determining the frequency of a word within a data set of texts. In combination with the Within Document Frequency, the Inverse Document Frequency helps to create unique content and may even replace keyword density as a quality score which has been used for a long time to determine text quality.
Background
In the mid-1960s, US researcher C. W. Clevedon has made significant accomplishments in his work “The Cranfield tests on index language devices” to research weighting. One aim of this work was to index existing documents better.
As a result, mathematicians and statisticians have always endeavored to find a suitable formula to determine the meaning of a word within a dataset of documents. While initially topics and the selection of certain words were considered, the view that all the words in a document have to be used for an analysis to determine the term weighting within an overall body of text finally prevailed. The IDF formula was ultimately the result of this research.
The Inverse Document Frequency is determined by a logarithmic calculation. It is the ratio of all existing texts and documents of an entire dataset and the number of texts that contain the defined keyword.
The calculation formula looks like this:
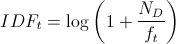
whereby file: CodeCogsEqn001.gif|link= denotes the number of documents and file: CodeCogsEqn-1.gif|link= contains the number of documents that contain the term file: CodeCogsEqn-2.gif|link=. If the document frequency grows, the fraction becomes smaller.
Benefits
The inverse document frequency alone can help to determine any peculiarity of a key term based on an existing document corpus. However, the term weighting within a dataset does not indicate anything about the uniqueness of the text.
Therefore, the formula TF*IDF is used in content optimization to be able to compare the result to a prior document. Important in the analysis is that such an analysis of websites not only takes into account the pure text corpus, but also any text embedded in the source code, and thus page titles and alt tags as well.